In 2026, Artificial Intelligence is no longer just a competitive advantage; it is a core operational requirement. However, as UK businesses increasingly integrate Large Language Models (LLMs) into their workflows, a massive concern has emerged: Data Privacy.
Sending your company's proprietary data, customer records, or internal code to public AI models like ChatGPT or Claude poses significant security and compliance risks. The ultimate solution to this problem is deploying Private LLMs on your own infrastructure. Here is why running open-source AI models on eServers' Dedicated GPU Hardware is the smartest move for your business today.
The Rise of Private LLMs
A Private LLM is an AI model that you host entirely within your own environment. Thanks to massive leaps in open-source AI, models like Meta's Llama series, Mistral, and Falcon now offer performance that rivals—and sometimes exceeds—closed, public models.
By running these models privately, you gain complete control. You can train them on your internal documents using Retrieval-Augmented Generation (RAG) to create highly customized AI assistants, secure coding copilots, or automated customer support bots—all without your data ever leaving your network.
Why Dedicated GPU Hardware Beats the Public Cloud
Running an LLM requires serious computational power, specifically GPUs (Graphics Processing Units) designed for parallel processing. While public cloud providers offer GPU instances, they come with significant drawbacks for sustained AI workloads.
This is where a bare-metal dedicated server from eServers steps in:
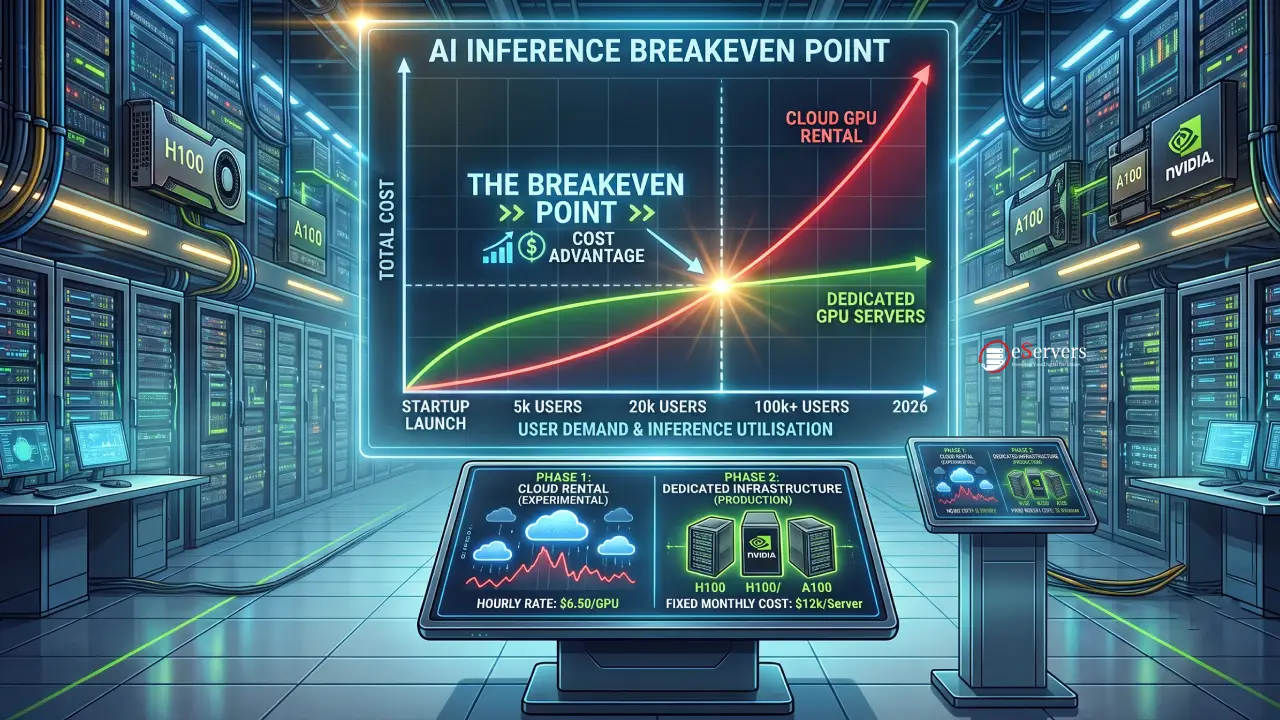
1. Predictable Cost vs. Bill Shock
Public cloud GPU pricing is notoriously volatile. Paying per hour or per token can lead to astronomical bills if your AI usage spikes. With an eServers dedicated GPU machine, you pay a predictable, flat monthly fee. Whether you generate a thousand tokens or ten million, your infrastructure cost remains exactly the same, resulting in a much higher ROI.
2. Unthrottled Raw Performance
Virtualised cloud GPUs often suffer from a hypervisor overhead and the "noisy neighbour" effect. On a dedicated eServers machine, you get 100% of the raw compute power. You have direct access to the PCIe lanes, CPU, NVMe storage, and the GPUs themselves. This translates to incredibly low-latency inference, meaning your AI applications respond to users in milliseconds, not seconds.
3. Absolute Data Sovereignty and GDPR Compliance
For UK enterprises, data compliance is strictly enforced. When you rent a dedicated server located in a UK data centre, you know exactly where your hardware physically sits. Your private LLM runs locally, and your sensitive data never crosses international borders or enters a third-party black box, keeping you fully compliant with UK GDPR regulations.
Deploying Your Private AI Infrastructure
Setting up a Private LLM on a dedicated GPU server is more accessible than ever. With modern containerization tools like Docker and frameworks like vLLM or Ollama, your development team can deploy powerful models in minutes.
eServers provides root access to your hardware, allowing you to optimize everything from the OS-level drivers (like NVIDIA CUDA toolkits) to resource allocation, ensuring your models run exactly as your business requires.
Conclusion: Take Control of Your AI Strategy
Relying on external APIs for your enterprise AI strategy means compromising on privacy and handing over control of your costs. By bringing your AI in-house, you protect your intellectual property while unlocking unlimited customization.
By combining the intelligence of open-source private LLMs with the raw, uncompromised power of eServers GPU Dedicated Hardware, you build an AI infrastructure that is fast, secure, and ready to scale with your business in 2026.
(eServers Note: Ready to build your private AI environment? Explore our range of high-performance, UK-based Dedicated GPU Servers designed specifically for heavy machine learning and LLM inference workloads.)
Frequently Asked Questions (FAQ)
How much does it cost to run a Private LLM compared to public cloud APIs?
Public APIs charge per token, meaning costs scale unpredictably with usage. With an eServers bare-metal GPU server, you pay a predictable, flat monthly fee, allowing unlimited token generation without any bill shock.
Is it difficult to set up open-source LLMs like Llama or Mistral?
Not at all. With full root access provided by eServers, your team can easily use modern containerization tools like Docker alongside frameworks like Ollama or vLLM to deploy powerful models in just a few minutes.
Does running my AI on eServers hardware help with UK GDPR compliance?
Yes. Since our dedicated servers are physically located in UK data centres, your sensitive data never crosses international borders or enters third-party systems, keeping you fully compliant with UK data sovereignty and GDPR regulations.
Can I train the Private LLM on my own company data?
Absolutely. You can use techniques like Retrieval-Augmented Generation (RAG) or fine-tuning to train open-source models on your internal documents, creating highly customized AI assistants securely on your dedicated hardware.